
Don’t let big companies own your metadata and data, take control and create your own personalized LLM with your own corpus of information.
The advancements in AI have been dramatic over the past few months. Midjourney and Stable Diffusion have increased in complexity, NERF can create three-dimensional experiences with just a series of pictures, and ChatGPT has transformed from a cool internet thing to a business that Microsoft is doubling down on.
I’ve been ramping up myself over the past few months, making everything from pictures to augment writing prompts, aprons for your summer cookout, and ambient music videos on YouTube. However, with the advancement of Large Language Models, and the algorithm behind ChatGPT, I think it’s time to incorporate more AI into my life.
Embeddings … it’s about the data
Large Language Models (LLMs) are trained on data. Massive voluminous amounts of data. ChatGPT is trained on 45 terabytes of data. Here’s what it has to say about itself:
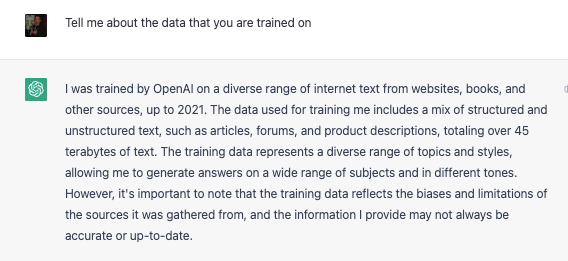
LLMs only know what has been fed as training data, so if you ask who is the current Representative of your district, it won’t know that, but it will be confident in the response, even if the answer is from 2021. When the model is trained, it uses embeddings to establish relationships between words and, in theory, concepts. I could explain it to you, but:
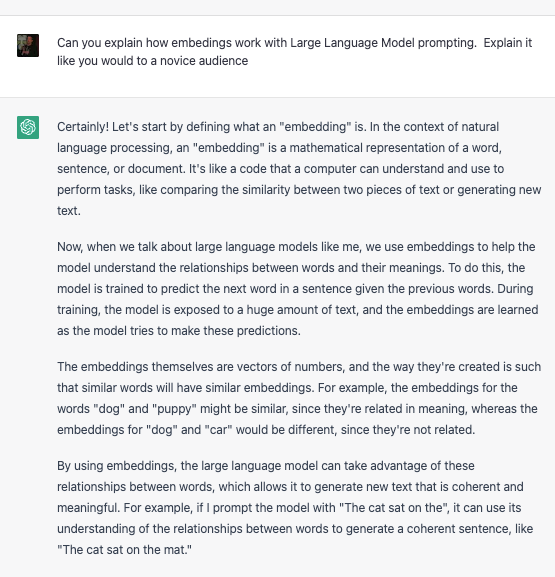

Now a couple of things jump out here. First off, LLMs are not always accurate. The computer is guessing … it doesn’t know what the next word or sentence means; it just knows that the vectors of the embedded tokens are close. So cars and Ford are close to each other, which is why they are related in the model’s response. The second thing is that the training data is the most critical part of the model. You could create a model that was only trained on Star Wars scripts, fan fiction, forum posts, books, etc. In that model, your Representative could be Queen Amidala, not Liz Cheney.
Neither answer is factually correct, but the model has no way of knowing that. It just understands the relationships between the words based on its training data. It also doesn’t know anything that isn’t in its model.
Metadata is blase … what you really need is your own corpus
In a previous article, I wrote about the importance of generating and tracking your own personal metadata.
Unfortunately, metadata is no longer enough. Right now, companies like Twitter and Facebook have metadata about what causes you to engage, Amazon has data about your monthly purchases, and Netflix has data about your viewing habits. But they do not have a way of capturing who you are in the same way that a Large Language Model can “know” who you are.
In the Black Mirror episode “White Christmas,” Jon Hamm portrays someone who trains a digital copy of a woman to act as the brain of her Smart Home. The story is a brutal episode, but it explains what embeddings could accomplish. Take everything that you have written via text, e-mail, or blogging. Convert your favorite movies and tv scripts to text or transcribe your journal. Training material could be provided from your work communications, or documentation from your most often used software programs can all be collected and then “tokenized” and embedded for your training data. Once you have this corpus of data, you can then add your metadata, i.e., times, places, people, how you felt, etc.
With that, you can ask questions like:
- “How do I create a video in Blender?”
- “Can you tell me what I was talking about with Susie in January?”
- “Can you offer some suggestions for me to watch, I’m feeling kinda of sad.”
- “That Black Mirror episode with Jon Hamm? What’s an interesting blog article to write about?”
If you don’t pay for a service, you are the service
Ok … so this is all feasible, but why should you start putting the time into collecting your data? Namely, Large Language Models are getting more accessible and easier to train. Large companies will have a leg up on training these models and will be looking for a way to monetize the capability.
If you don’t want large companies owning the metadata and training data that will make these tools helpful, this is a great way to stay ahead of them without sacrificing your privacy.
